
 Twitter
Twitter Slack
Slack RSS
RSS GitHub
GitHubDead container walking: making a case for Kubernetes Object Status
As a Kubernetes practitioner, you may be familiar with kubectl and how to interpret the results you get from a very common command like:
# kubectl get pods
# NAME READY STATUS RESTARTS AGE
3scale-kourier-control-54cc54cc58-px2dt 1/1 Running 3 4d2h
activator-67656dcbbb-hq62r 0/1 Running 161 4d2h
autoscaler-df6856b64-blxgm 1/1 Running 1 4d2h
But in case you are not, it could be challenging to accurately diagnose the behavior shown in the above example: the activator Pod is in a Running status but none of its containers are Ready.
How could it be?
It all comes to the way the Kubernetes API handles Pod lifecycle
POD lifecycle details
According to the
official docs, the Kubernetes API has a PodStatus object with a field called Phase but there’s also the container State field that Kubernetes tracks.
When you run:
~$ kubectl get pods
The Status column in the command output takes into account the container State that is a more granular measurement in comparison with the Pod phase which is a high-level summary of where is the Pod in its lifecycle.
While there are five possible values for Pod phase:
| Value | Description |
|---|---|
| Pending | Configuration accepted by the server but not ready to run (e.g. init containers, pending image fetching, among others) |
| Running | All of the Pod’s containers created, at least one of them is running |
| Succeeded | All containers successfully completed their task and then exited, especially true in the presence of OnFailure restartPolicy |
| Failed | All containers terminated and at least one terminated in failure |
| Unknown | Most likely the node is offline |
There are also three container states defined in the Kubernetes API:
| Value | Description |
|---|---|
| Waiting | A task is pending to complete, for example a container image download or an init container still running |
| Running | Container executing with no issues nor pending tasks |
| Terminated | Container either ran to completion or it failed |
With all these possibilities, one could argue that a better approach to diagnose the situation of a Pod is to measure it both at the container and the Pod level.
And that is what the 0.23 version of Octant enables users to do.
Octant and the Status field
Apart from the Phase field that Octant has traditionally displayed for each resource in the Kubernetes environment, the 0.23 release has added the Status column which -in the case of Pods- refers specifically to the container State.
So, if we take a look at the activator Pod with Octant:
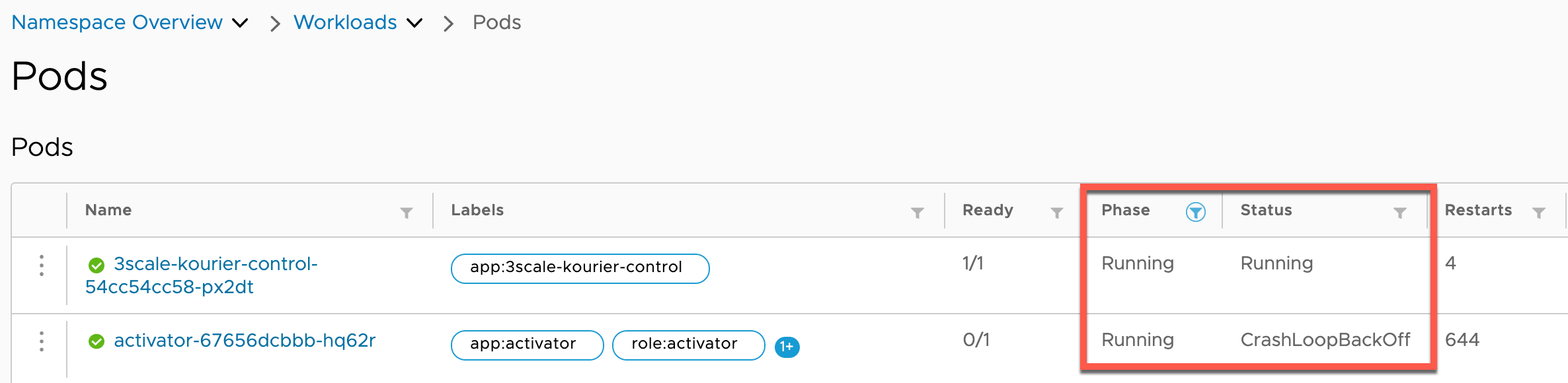
We can see that it’s in the Running phase, but the actual container state is CrashLoopBackOff which means that the Kubelet has successfully started it several times but has crashed afterwards without reaching a stable state yet.
Using Octant we can isolate the root cause of the issue:
- Click on the Pod name
- Go to the Resource Viewer tab and there you will find the Last Event field:
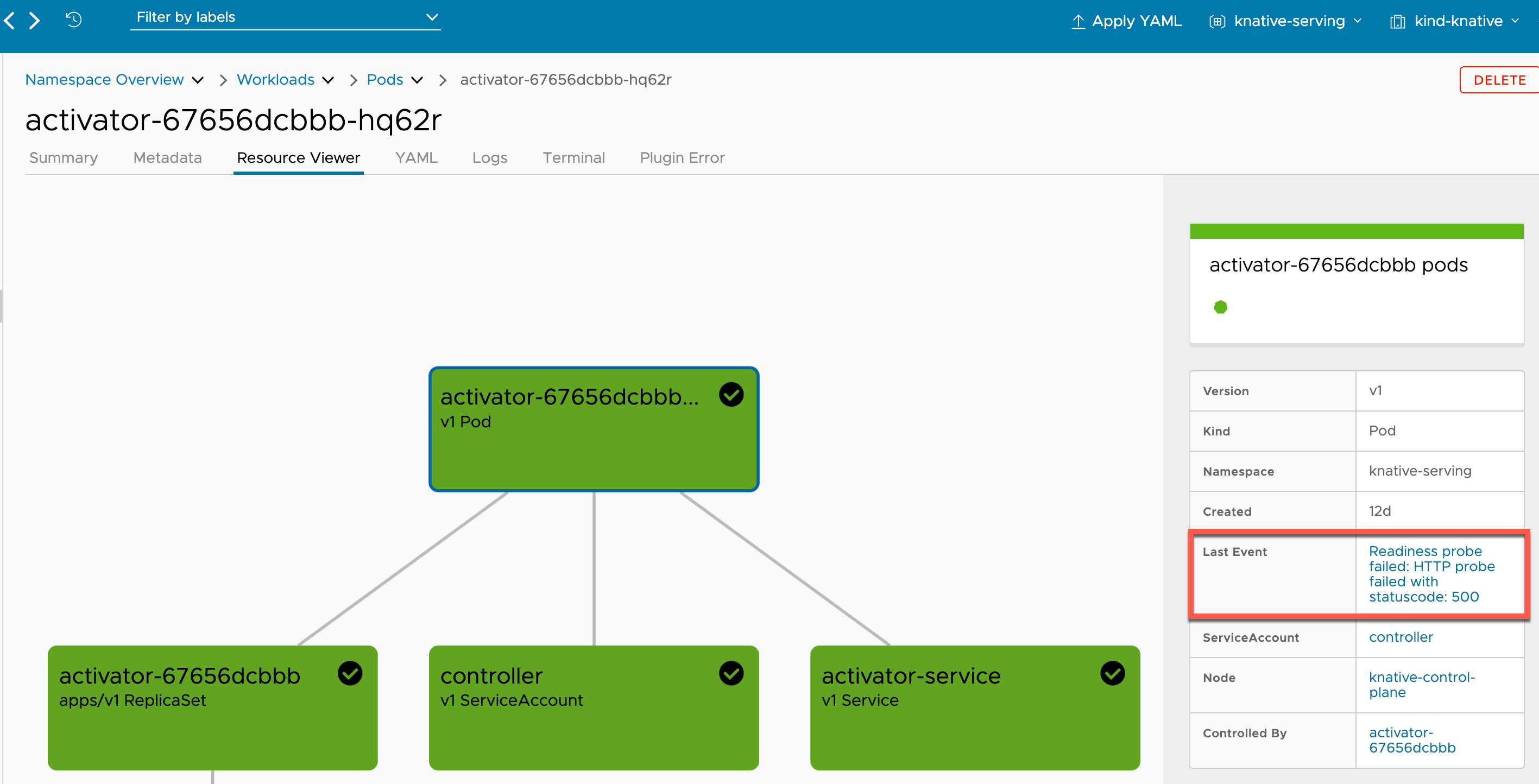
According to this Event, one could infer that the Pod is failing to perform a HTTP connection to another service and is dependent of that connection to start successfully
- Go to the Logs tab to gather more details about the Readiness Probe failure:
{"severity":"ERROR","timestamp":"2021-09-08T20:22:54.283557107Z","logger":"activator","caller":"websocket/connection.go:192","message":"Failed to send ping message to ws://autoscaler.knative-serving.svc.cluster.local:8080","commit":"c75484e","knative.dev/controller":"activator","knative.dev/pod":"activator-67656dcbbb-hq62r","error":"connection has not yet been established"
The activator Pod depends on a successful connection to the autoscaler.knative-serving.svc.cluster.local service through the 8080 port to start successfully.
- Taking a look at the
autoscalerPod logs :
{"leaderelection.go":"Failed to update lock: Operation cannot be fulfilled on leases.coordination.k8s.io", "autoscaler-bucket-00-of-01":"," "the object has been modified; please apply your changes to the latest version and try again"}
As you have may have noticed, this is a Knative environment and -in this case- the leader election mechanism implemented using the coordination.k8s.io API and the leader election package in the Go SDK, is failing.
Further testing from the activator Pod showed a DNS resolver issue that could explain why the connection hasn’t been established:
~$ kubectl -it activator-67656dcbbb-hq62r -ns knative-serving-- nslookup autoscaler.knative-serving.svc.cluster.local
~$ server can't find autoscaler.knative-serving.svc.cluster.local: NXDOMAIN
This problem seems to fall into the category of the Kubernetes DNS resolution known issues
- After passing a custom
resolv.confto the kubelet, the connection is now successful, theautoscalerPod is able to run and theactivatorPod reaches the Running state:

Final thoughts and call to action
One of the original goals of Octant is to be a visual aid to kubectl to rapidly display the relationships between resources in your Kubernetes clusters and thus accelerate troubleshooting for cloud native applications. Leveraging all the details the Kubernetes API can provide in terms of Object Status is a stepping stone to fulfill that mission.
If you haven’t, upgrade Octant to the latest version and let us know your thoughts, feature requests, issues, and comments in the Octant repo
Thank you!
The Octant Community Management team
P.D.
If you are an Octant user, please consider adding a few details around your organization and use cases to this discussion so we can promote you publicly as an Octant adopter!
Related Content
Kubernetes: There is an app for that
With release 0.17, Octant is available as a desktop application fully packed with new features: improved Navigation, Breadcrumbs, Preferences and much more.
Octant 0.14 - Now with Resource Creation
Octant now supports the ability to create resources for 0.16+ Kubernetes clusters and more!
Octant 0.10 - New Year, New Features
In a perfect world, you would deploy applications to clusters and nothing else would be a problem. In the Kubernetes world, it isn’t that simple yet.